


¡Aquí tienes la primera entrega de 3 superpost de Resumen de Estadística! No pierdas más el tiempo en buscar en internet. Tienes el resumen de Estadística definitivo. Este post está diseñado para que sigas un camino conceptual que va desde 0 conocimiento a saber manejarte con una variable numérica. Ten paciencia en el próximo mes te presentaré las dos entregas que faltan. ¡Disfrútalo!
Tabla de contenidos
Introducción a la Estadística
La ESTADÍSTICA es una ciencia que te permite tener una mejor interpretación de los fenómenos que observas. Te ofrece herramientas para estudiar y evaluar acontecimientos reales a partir de datos.
La ESTADÍSTICA tiene un sinfín de aplicaciones. Sólo necesitas observaciones de acontecimientos reales. La ESTADÍSTICA te proporcionará una valoración OBJETIVA. Aprenderás gracias a los datos.
La ESTADÍSTICA responde a preguntas y tiene un OBJETIVO definido detrás de cada aplicación.
¿Quieres saber ejemplos de aplicación?
¿Quieres saber las etapas en una INVESTIGACIÓN ESTADÍSTICA?

Datos y variables
Para conseguir un OBJETIVO, la ESTADÍSTICA utiliza DATOS obtenidos a partir de observar la realidad. La ESTADÍSTICA se encargará de aprovechar los DATOS: los traducirá y los evaluará para que aprendas y tomes decisiones.
Los DATOS son observaciones de VARIABLES. Por ejemplo: la altura, el peso, el coeficiente de inteligencia, la calidad del vino, la velocidad del viento, la lluvia por metro cuadrado, el país de origen ...
La tabla de datos. Antes de usar la estadística ordena tus datos en una tabla

Tipos de variables. Aprende qué variables puedes observar

Muestra y población
Se pueden RECOLECTAR datos directamente observando la realidad o de un experimento controlado y concreto.
- Observa la realidad. Por ejemplo guarda los datos de la velocidad de viento media diaria durante 1 mes. Observas cada día que valor de velocidad media tienes- Al final del mes obtienes 30 observaciones.
- Crea tu propio experimento. Muy típico en medicina, biología. Un experimento: dos grupos de personas. Uno de los cuáles toma un fármaco y la otra no. Quieres ver si el fármaco es efectivo o no. Si el fármaco es efectivo quieres inferir los resultados de este grupo a toda la población.
Imagina que quieres evaluar el salario medio de un habitante de la ciudad de Barcelona. En lugar de RECOLECTAR los datos observando toda la POBLACIÓN de Barcelona prefieres escoger un pequeño grupo de personas, una MUESTRA.
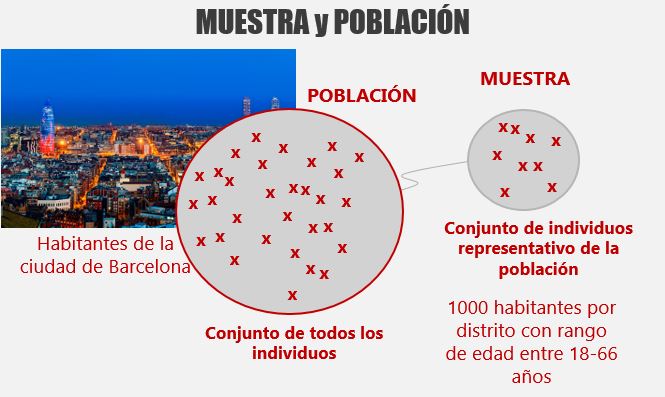
Escogiendo la muestra
El hecho de escoger una muestra de la población es llamado MUESTREAR.
- Muestra aleatoria. Se trata de escoger la muestra al azar. Todas la teorías de la inferencia estadística son validas si la muestra es aleatoria.
- Muestreo por etapas. La idea es mostrear aleatoriamente por etapas de mayor a menor entidad. ¿No has entendido nada? Lo vemos en un ejemplo:
- Muestreo estratificado: se trata de muestrear aleatoriamente según un estrato con una determinada proporción en la población.
Debes seleccionar qué estratos son importantes para tu investigación.
Las dos ramas de la estadística
Ligado al concepto de TABLA DE DATOS...
ESTADÍSTICA DESCRIPTIVA. La tabla de datos no te dice nada a simple vista. Es necesario describir los datos mediante gráficos o valores que los resuman.

Ligado al concepto de muestra y población ...
ESTADÍSTICA INFERENCIAL. Los datos de una muestra puden ser válidos o no. ¿Todos los estudios que haces en una muestra son representativos de toda la población?
Analizando una variable numérica
En esta sección tienes información de cómo DESCRIBIR UNA variable numérica. Es parte de la estadística descriptiva.
Histograma y distribución
El histograma es un gráfico de barras y te da la idea de cómo esta distribuida la variable.
Para dibujar un histograma necesitas saber el número de BINS o clases.
Las clases son intervalos numéricos. Cada barra del histograma tiene su clase asignada.
La altura de cada barra es la frecuencia. La frecuencia es el número de observaciones que están dentro de una clase. Por cada clase tienes un valor de frecuencia. Mira el post del histograma 😀 encontrarás algún ejemplo de la tabla de frecuencias.
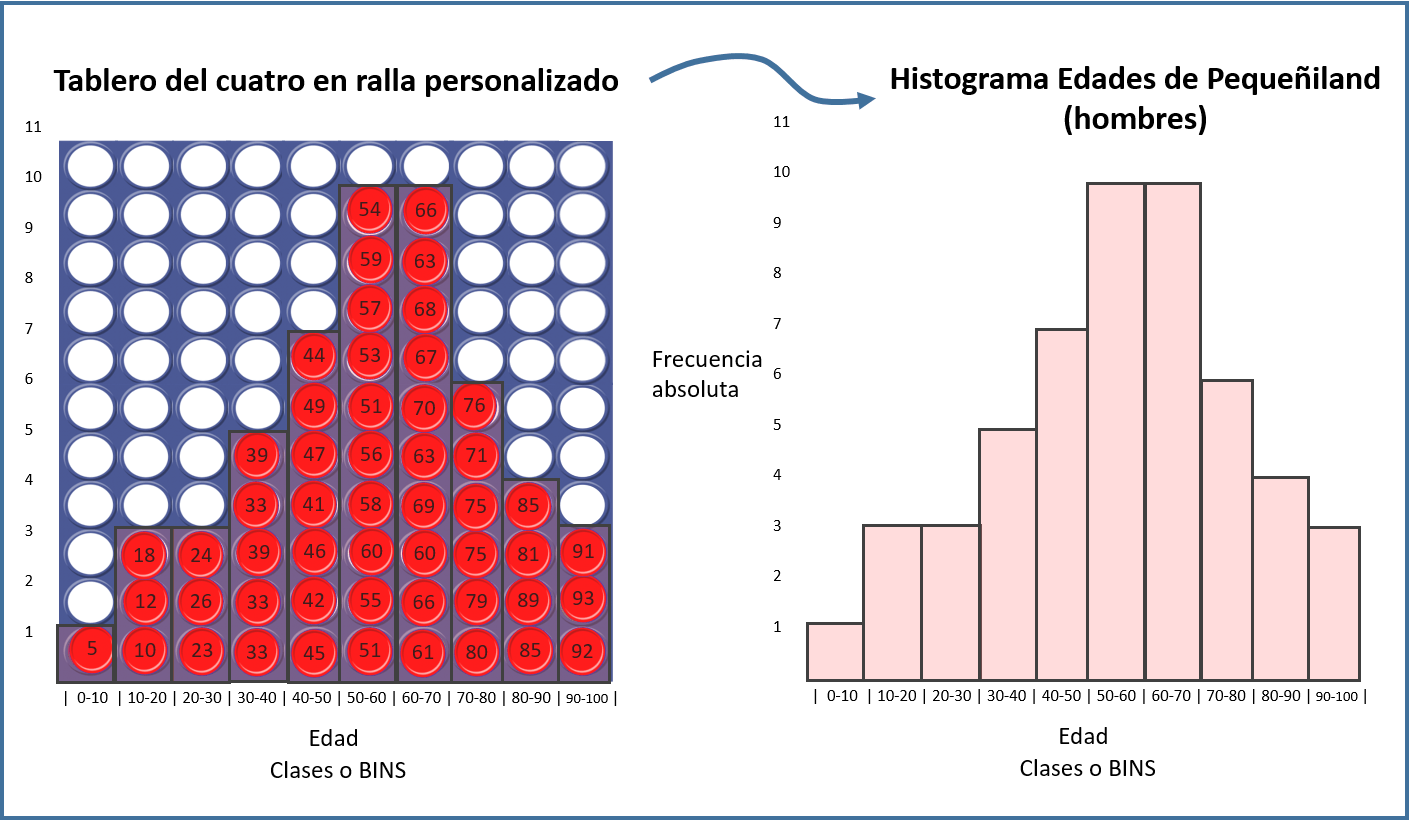
La distribución de una variable numérica es el contorno de un histograma.
Densidad de probabilidad
Puedes dibujar el histograma de densidad: el área de todas las barras suma 1. Las unidades del eje "y" son densidades. Se expresan como frecuencia absoluta/unidad de la variable numérica.
Te pongo un ejemplo. Estoy pintando el histograma de una muestra aleatoria de una población de personas. Estoy mirando sus alturas en cm. (Puedes descargarte el ejemplo en R 😀 )
Imagina que tienes una muestra aleatoria de 100 observaciones y dibujas el histograma de densidad.

Imagina que tu muestra es más grande y tenemos 1000 observaciones y dibujas el histograma de densidad.

Imagina que tu muestra es más grande y tenemos 10000 observaciones y dibujas el histograma de densidad.
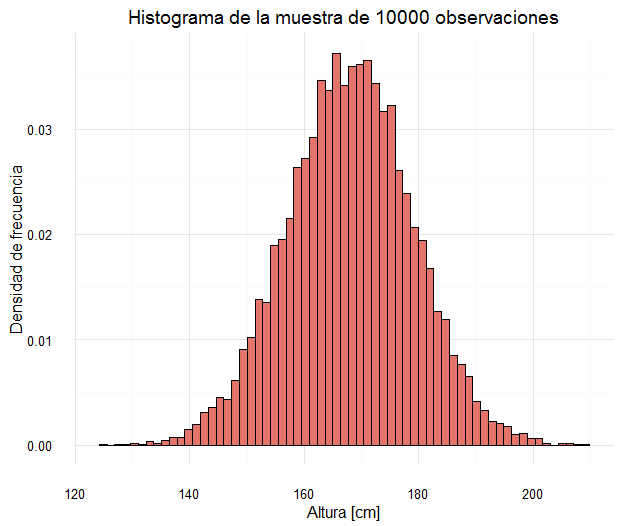
Con toda la población obtenemos un histograma con clases super pequeñas. Podemos dibujar un contorno.


- La función de densidad de probabilidad no es más que un histograma de densidad llevado al límite.
- El contorno de este histograma es una densidad de probabilidad. Es una función teórica.
- Su nombre es debido a que el área debajo la distribución de densidad de probabilidad es la probabilidad. El área total de la distribución de probabilidad es 1. Es la probabilidad total.
- Para calcular probabilidades hay que calcular el área debajo la curva (es decir la integral de la función densidad de probabilidad).
- La distribución de densidad de probabilidad es una ley teórica de la población. En mates es una función continua.
Medidas para describir la distribución
MEDIDAS DE CENTRALIDAD
- LA MEDIA es el valor del punto de equilibrio de los datos (de la distribución)
Imagina que tus datos son el peso en kg de un grupo de 30 personas. La media parte el grupo en dos. El peso total de cada grupo será el mismo.
- LA MEDIANA es el valor que parte en dos grupos los datos. Estos tienen el 50% en número de datos cuando los tienes ordenados de pequeño a grande.
El área debajo de la distribución es igual a la derecha que a la izquierda de la mediana.
- LA MODA es el valor más repetido de la variable numérica.
MEDIDAS DE DISPERSIÓN y POSICIÓN
- EL CUARTIL 25 es el valor que parte en dos grupos los datos. Un grupo tiene el 25% de los valores más pequeños y el 75% son valores más grandes.
- EL CUARTIL 50 es LA MEDIANA
- EL CUARTIL 75 es el valor que parte en dos grupos los datos. Un grupo tiene el 75% de los valores más pequeños y el 25% son valores más grandes.
- RANGO INTERCUARTÍLICO (IQR): es la diferencia entre Q3 - Q1
- DESVIACIÓN ESTÁNDAR y VARIANCIA es el valor de la dispersión a la media. Es la media de la suma de las distancias a la media.
- EL MÁXIMO, EL MÍNIMO y EL RANGO también son medidas de dispersión. (El rango es las distancia entre el mínimo y el máximo)

¿Para qué sirve la media y la mediana?

¿No entiendes que es la dispersión de una distribución? ¡Mira esto!

¿Quieres fórmulas? No te asustes son fáciles 🙂

Características de una distribución
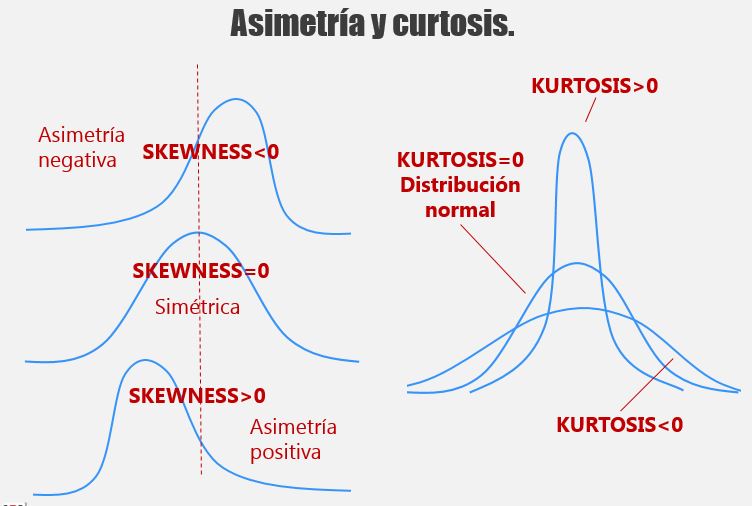
Las dos medidas más utilizadas para describir la forma de una distribución son:
Asimetría. ¿Es la distribución simétrica o no? Un ejemplo de distribución simétrica es la distribución Normal.
Curtosis o medida de la centralidad. ¿Tiene valores centrados o son dispersos? ¿Es la distribución ancha o estrecha?
Gráficos descriptivos de una variable
- Histograma
Es el diagrama de barras por excelencia. Te permite saber muy rápidamente cómo está distribuida tu variable numérica. La variable numérica se divide en intervalos o clases y se dibuja una barras por clase. Cada barra corresponde a la frecuencia de ocurrencia.
- Diagrama de frecuencias
El diagrama de frecuencias es equivalente al histograma. Es la unión de las barras mediante una línea. Te da información de cómo está distribuida tu variable. Es un diagrama de línea que te permite comparar dos o más variables numéricas y ver su distribución.

- La nube de puntos (este me lo he sacado de la manga)
Simplemente representas los valores de la variable numérica en puntos para hacerte una idea de el rango de la variable, el valor mínimo el máximo y la dispersión.

- Box-plot
Este gráfico es muy interesante. Trabaja con los valores del cuartil1, mediana o cuartil2, cuartil3. Además utiliza el valor máximo y mínimo así cómo refleja valores anómalos.
Este gráfico te da una idea muy clara de cómo se distribuye tu variable numérica.

- QQ-plot
Es un gráfico que te permite:
- Ver si muestra es cercana a la distribución teórica que esperas.
- Comparar dos muestra numérica y ver si tienen una distribución parecida
Se pintan los valores de los cuartiles de tu variable numérica en función de los cuartiles de la distribuicón teórica que quieres comparar o la variable numérica que quieres comparar.
Una de las prácticas más utilizadas es para saber si una variable numérica está cerca de la distribución normal.

NO TE VAYAS SIN DESCARGARTE UN EJEMPLO
¡Aquí tienes el primer superpost! No pierdas más el el tiempo en buscar en internet. Tienes el resumen de Estadística definitivo. Este post está diseñado para que sigas un camino conceptual que va desde 0 conocimiento a un bueno. Sino entiendes alguna cosa ves para arriba para encontrar el significado. No olvides de ponerlo en favoritos. Lo vas a agradecer. ¡Ya lo verás!
¿Te ha servido el post? Está resumido lo sé, pero ¿se entiende bien?






Muchas Gracias Jordi! Excelente material, muy claro todo…
Para eso está! 😉
CUAL ES LA MEDIDA MAS ADECUADA PARA CENTRALIZAR LOS DATOS
Hola Gilary!
Las medidas de centralidad pueden ser la media o la mediana.
Si tienes distribuciones en forma de montaña. Es decir un histograma simétrico parecido a la distribución normal utiliza la media.
Si tienes distribuciones diferentes a la distribución en forma de montaña utiliza la mediana.
Si lo que quieres es centralizar los datos. Es decir escalar los datos. Lo mejor es quitar la media y dividir por la desviación estándar. (X-Media)/Desviación Estándar.
De esta manera conseguirás tener la variable numérica centrada en 0 y desviación estándar 1.
Espero que te sirva!
Un abrazo!
gracias jordi muy bueno
De nada Rafael!
Gracias por comentar!
Este material es justo mi idea que en un correo te comente
Creo que esto es lo que hay que enseñar como un razonamiento logico-estadistico
o como logico-investigativo.
Con C2 y ejemplos cocinados poder desarrollar en el estudiante ese ojo que le permita
al futuro investigador dejar que los datos hablen.
Claro concidero que es previo a quererlo hacer investigador
Gracias Roberto!
ültimamente he recibido muchos emails y voy un poco liado. A lo mejor se me ha saltado alguno!
Gracias por tus mensajes!
Una vez mas gracias Jordi, entendí de maravilla todo ahora falta llevarlo a la práctica es verdad que es inconcebible un profecional que no domine aunque sea un poco la estadistica saludos Ernesto R
Gracias Ernesto!
Poco a poco vamos avanzando!
1 placer!
Hola Jordí, los comandos para los para dibujar el boxplot, el qqplot mediante plotly no están en el R que se descarga.
Podrías enviarmelos?.
Alan
Están a bajo del código 🙂
# Dibujamos el boxplot de x
plot_ly(y = muestra[,1], type = «box»,name = » «)%>%
layout(title = «Box-Plot»,yaxis = list(title = «Muestra X»))
# Dibujamos el qqplot de x
gg_qq(x,distribution = «norm»,labels = «x»)
Excelente post Jordi! Estoy comenzando a meterme en el mundo del machine learning y en la mayoría de los tutoriales y kernels utilizan estos conceptos pero sin explicarlos. Este post me ha servido de maravilla para recordar conceptos que hace un tiempo estudié en facultad pero que tenía un poco olvidados, y son fundamentales para meterse en el mundo de la ciencia de datos. Muchas gracias y saludos desde Uruguay!
¡Claro que sí!
Es importante volver a las bases y asentarlas.
Es el primer tema de mi programa formativo de pago Analiza tus Datos y es completamente esencial 🙂
Más info:
https://events.genndi.com/register/818182175026331371/ae98d21b5c
Abrazos!